

First let's see how we can perform a single simulation, then we will see how to perform multiple simulations and visualize the Weak Law of Large Numbers.
Single Simulation 
Say that you want to know the average height of your classroom students. There are
\(300\)
students and you want to know, what is the average height of those \(300\)
students?You can't measure height of all
\(300\)
students, so you took small sample of \(50\)
students and measure their heights. Suppose that the average height of those \(50\)
students (sample mean) is somewhat near to the average height of all \(300\)
students (true mean). So the population size
\((N)\)
is \(300\)
and sample size\((n)\)
is \(50\)
. Remember that dogma
Truth
Now let's define the truth.Say that the each student's height follows the Normal distribution with mean
\((\mu)= 175 \text{cm}\)
and variance \((\sigma^2)=(10\text{cm})^2\)
. So
\(X_1,\cdots,X_{50}\sim\mathcal{N}(175,10^2)\)
Here we can argue that Normal distribution take values between\((-\infty,\infty)\), but heights aren't negative.
Clarification:
Yes\(\mathcal{N}(175,10^2)\)can take negative values but for\(\mathcal{N}(175,10^2)\)probability of taking negative values in insanely small.
Probability
Here we apply probability to generate data using the Truth we defined above.Now let's create the population of all
\(300\)
students. import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm # to draw random variables from Normal distribution
N = 300 # population size
true_mean = 175 # average height of all 300 students
standard_deviation = 10
# For clarification:
# Our notation of Normal distribution is N(mean, variance)
# And scipy.stats.norm notation is N(mean, standard_deviation)
distribution = norm(true_mean, np.sqrt(standard_deviation))
population = distribution.rvs(N)
Observation
Now that we have all\(300\)
students, and every student's height follows the Normal distribution with mean \((\mu)= 175 \text{cm}\)
and variance \((\sigma^2)=(10\text{cm})^2\)
. Let's (randomly) take a sample of
\(50\)
students. n = 50
sample = np.random.choice(population,n)
Statistics
So now that we have our sample of\(50\)
students, let's estimate the average height of those \(50\)
students (sample mean). sample_mean = np.mean(sample)
But wait this is not the Weak Law of Large Numbers, it's just a sample mean.
Exactly this is not the Weak Law of Large Numbers, but to visualize the Weak Law of Large Numbers we just need to perform this simulation with increasing sample size
\((n)\)
and see if our sample mean converges to \(175\text{cm}\)
. So let's dive into it.
Multiple simulations
The truth is that every student's height follows the Normal distribution with mean \((\mu)= 175 \text{cm}\)
and variance \((\sigma^2)=(10\text{cm})^2\)
. First create a population
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm # to draw random variables from Normal distribution
np.random.seed(1)
N = 300 # population size
true_mean = 175 # average height of all 300 students
standard_deviation = 10
# For clarification:
# Our notation of Normal distribution is N(mean, variance)
# And scipy.stats.norm notation is N(mean, standard_deviation)
distribution = norm(true_mean, np.sqrt(standard_deviation))
population = distribution.rvs(N)Now take sample mean for
\(n=1\)
to \(n=300\)
then plot them and observe the trend. Do the sample mean converges as sample size \((n)\)
increases? sample_mean = [] # sample mean for each n
for n in range(N):
sample_mean.append(np.mean(population[:n+1]))
x_axis = [i+1 for i in range(N)] # [1,2,...,N]
plt.plot(x_axis, population, 'o', color='grey', alpha=0.5)
label = f'$\\bar X_n$ for $X_i \sim N({true_mean},{standard_deviation})$'
plt.plot(x_axis, sample_mean, 'g-', lw=3, alpha=0.6, label=label)
plt.plot(x_axis, [true_mean] * N, 'k--', lw=1.5, label='$\mu$')
plt.vlines(x_axis, true_mean, population, lw=0.2)
bbox = (0.0, 1.0 , 1.0, 0.1)
legend_args = {'ncol': 2,
'bbox_to_anchor': bbox,
'mode': 'expand'}
plt.legend(**legend_args, fontsize=12)
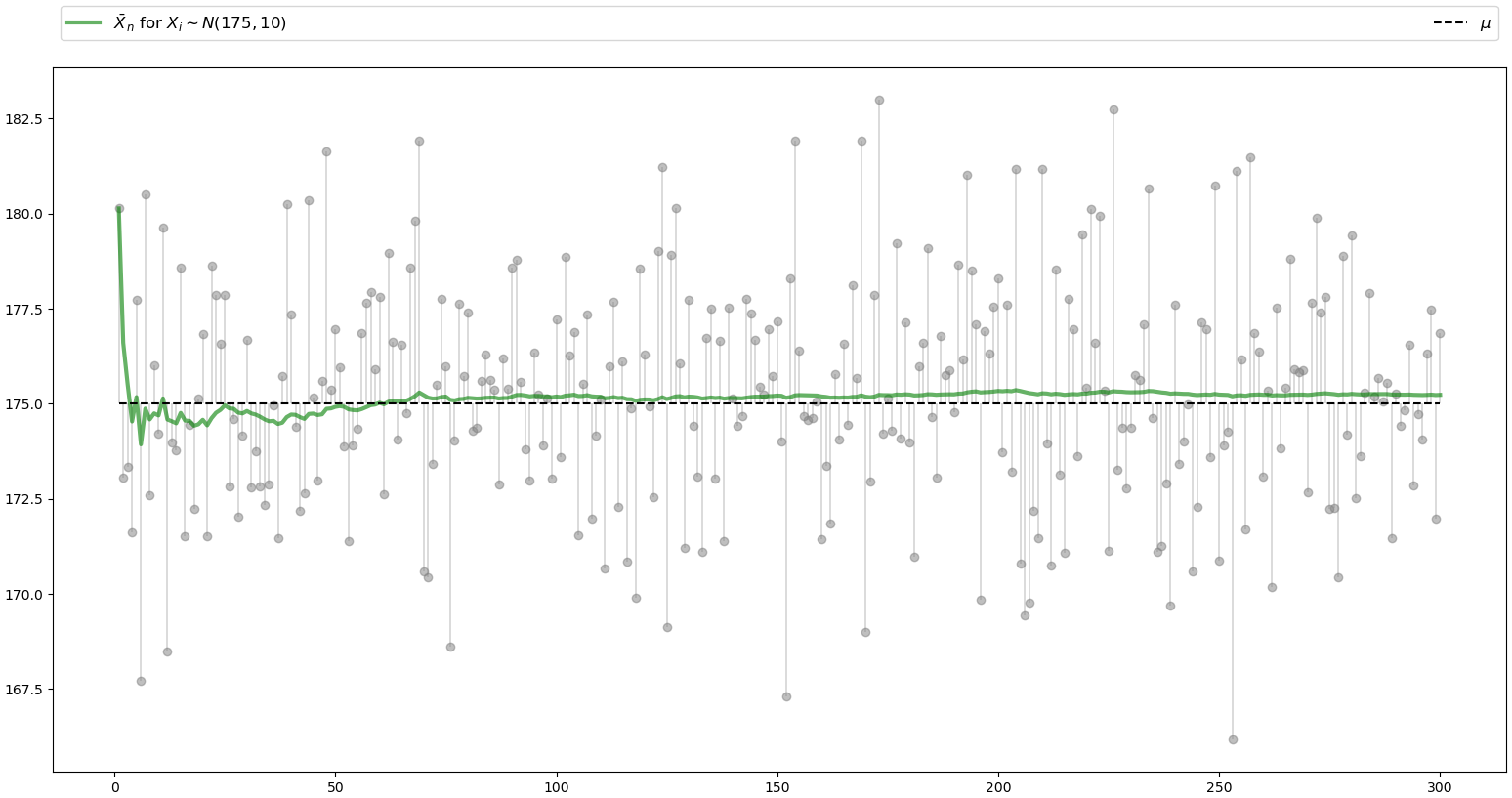
x-axis represents number of students
y-axis represents random variable
Here in this simulation we can see that as \((n)\)
y-axis represents random variable
\(\overline{X}_n\)
\(n\)
increases \(\overline{X}_n\)
do approaches to \(\mu\)
. Try playing with parameters, also try different distributions.
Simulation
Visualize Weak Law of Large Numbers
Try different distributions, tweak there parameters, and see how it impacts the convergence of\(\overline{X}_n\).