

First let's see how we can perform a single simulation, then we will see how to perform multiple simulations and visualize the Weak Law of Large Numbers.
Single Simulation 
Assume that there are \(1000\)
students in your school and you want to know, what is the average height of \(100\)
randomly selected students and how is that average height distributed (or say the distribution of that average height)?Remember that dogma
Truth
Now let's define the truth.Say that every student's height follows the Uniform distribution with range of
\([165\text{ cm },185\text{ cm}]\)
. So
\(X_1,\cdots,X_{50}\sim\text{Unif}[165, 185]\)
Note: This information is completely unknown to us.
Probability
Here we apply probability to generate data using the Truth we defined above.Now let's create the population of all
\(1000\)
students. using Plots, Distributions, Random, Statistics, StatsBase
N = 1000 # population size
a = 165 # Left limit of Unif[a, b]
b = 185 # Right limit of Unif[a, b]
distribution = Uniform(a, b)
population = rand(distribution, N)
Observation
Now that we have all\(1000\)
students, and every student's height follows the Uniform distribution. Let's (randomly) take a sample of
\(100\)
students. n = 100
sample_ = sample(population,n)
Statistics
So now we have our sample of\(100\)
students, let's estimate the average height of those \(100\)
students (sample mean). sample_mean = mean(sample_)
\(100\)
randomly selected students. Now let's see how the distribution of the average height of
\(100\)
randomly selected students look like. To achieve this we need to perform this simulation multiple times and plot all sample means as a histogram.
Multiple simulations
The truth is that every student's height follows the Uniform distribution \(\text{Unif}[165, 185]\)
, so let's start with creating population. using Plots, Distributions, Random, Statistics, StatsBase
gr(fmt = :png, size = (1540, 810))
Random.seed!(0)
N = 1000 # population size
a = 165 # Left limit of Unif[a, b]
b = 185 # Right limit of Unif[a, b]
distribution = Uniform(a, b)
population = rand(distribution, N)
Now let's collect n_simulations sample means of sample size
\((n) = 30\)
. (say n_simulations = 500)
n = 30
n_simulations = 200
sample_means = Array{Float64}(undef, n_simulations)
for i = 1:n_simulations
sample_means[i] = mean(sample(population,n))
end
num_bins = 50
Plots.xlabel!("Sample mean")
Plots.ylabel!("# occurrences of sample mean")
Plots.histogram(sample_means, bins=num_bins, label=false)
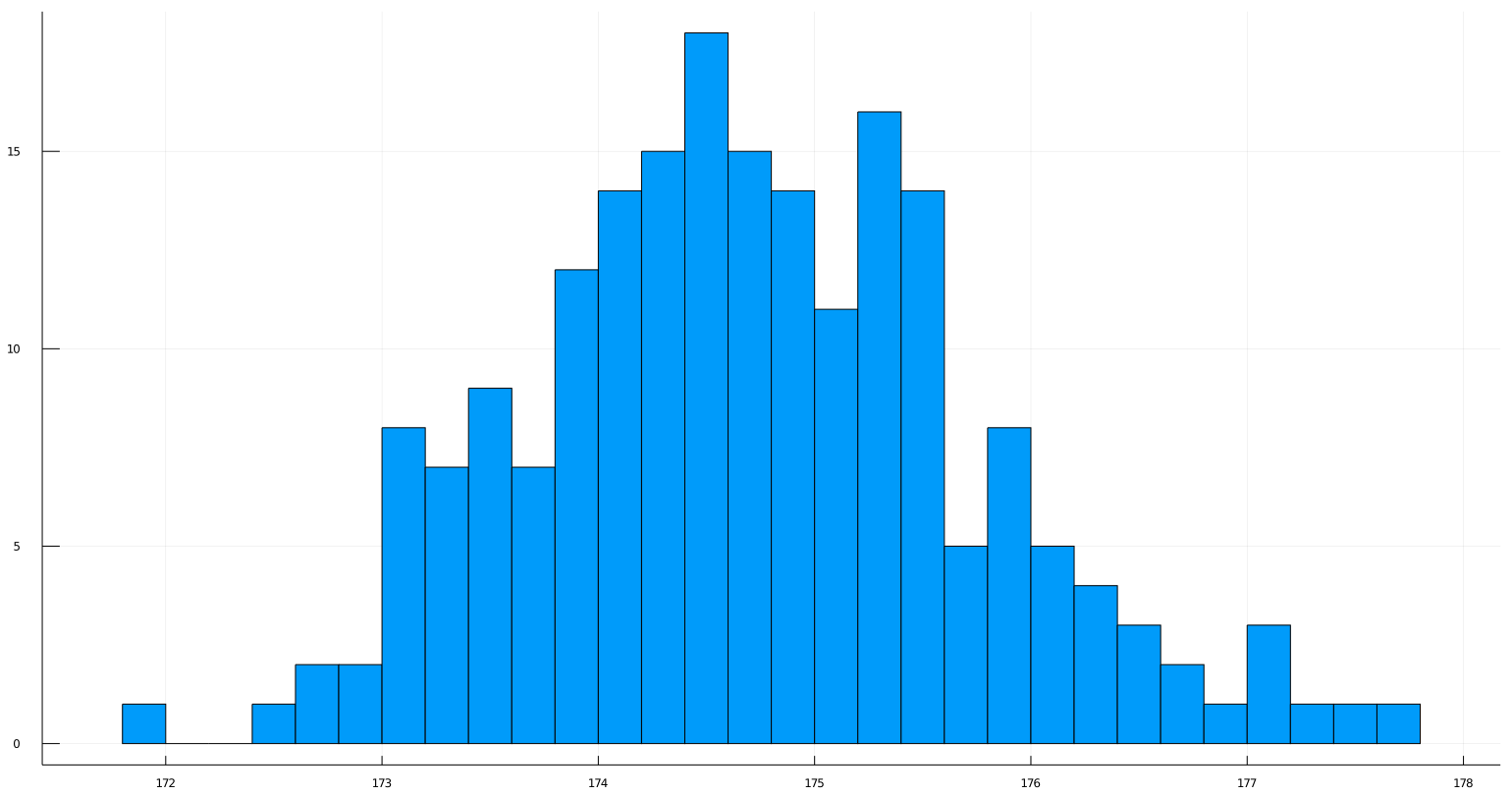
Sample mean seems to be normally distributed.
Well it's a Central Limit Theorem Simulation right, and the whole point of CLT is to approximate probability distribution of sample mean \(\overline{X}_n\)
to it's corresponding Normal distribution, am I correct? Let's see ourselves. Let's overlay a Normal distribution with true mean and variance of sample_means.
samples_mean = mean(sample_means)
samples_std = std(sample_means)
# Getting PDF
x = LinRange(samples_mean - 3*samples_std, samples_mean + 3*samples_std, 100)
pdf_ = pdf.(Normal(samples_mean, samples_std), x)
plot(x, pdf_, c="green", label="Normal distribution (PDF)", lw=3)
# Getting Histogram
num_bins = 50
bins = Array(LinRange(minimum(sample_means), maximum(sample_means), num_bins))
h = fit(Histogram, sample_means, bins)
counts = h.weights
Plots.histogram!(sample_means, bins=bins, weights=(1/sum(counts)).*ones(length(sample_means)))
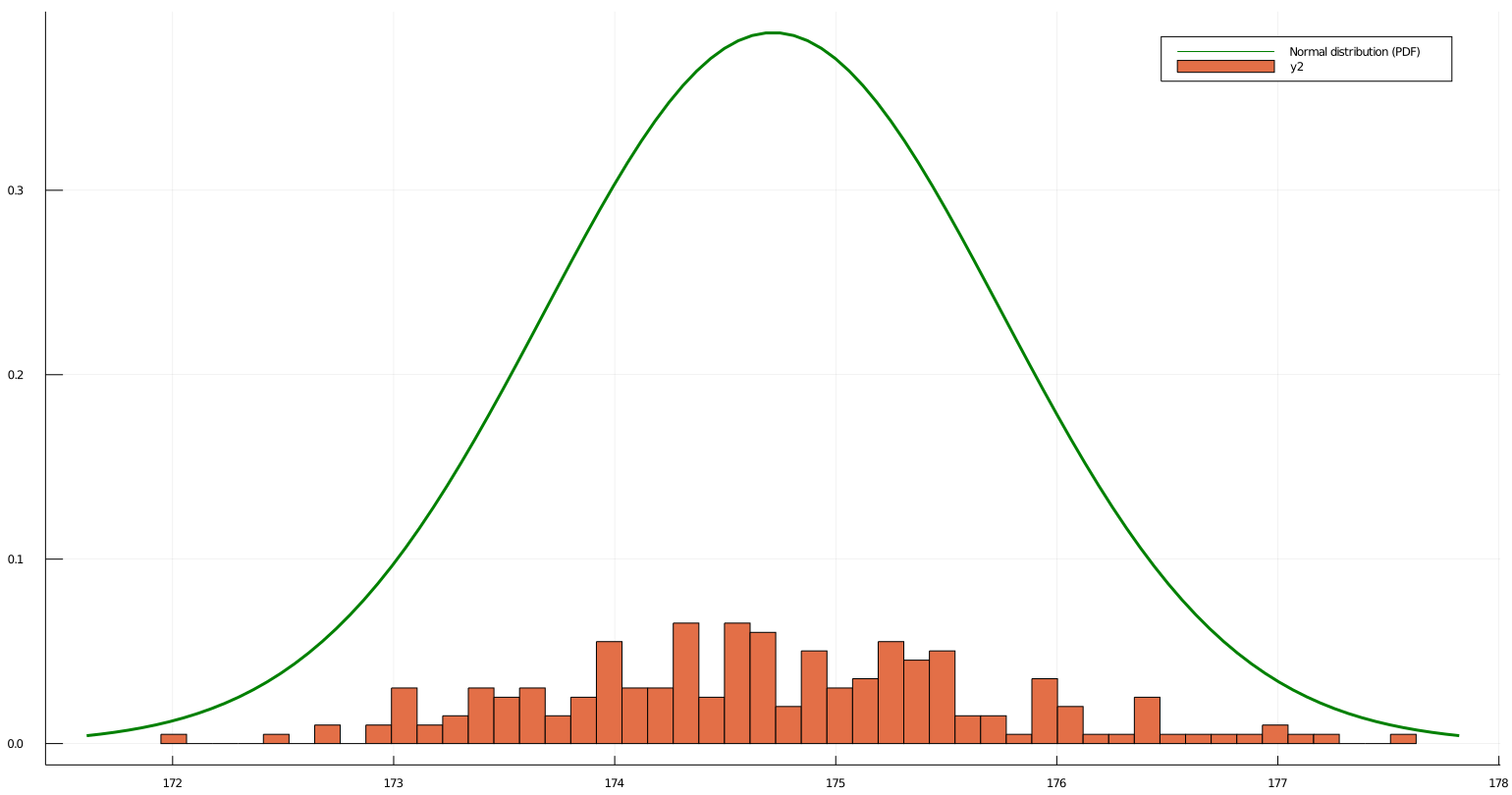 Here height of the bins of Sampling distribution represent the probability of falling into that bin.
Here height of the bins of Sampling distribution represent the probability of falling into that bin. The Normal distribution that we plotted have same mean and variance as of our Sampling distribution, but their shapes are way off.
Sampling distribution of \(\sqrt{n}\, (\overline{X}_n-\mu)\) is much better fit for Normal distribution
If you follow the result of the CLT,\[\sqrt{n}\, (\overline{X}_n-\mu) \xrightarrow [n\to \infty ]{(d)} \mathcal{N}(0,\sigma^2) \]Then you can see our normally distributed data.
We just have to center our observations around\(0\)and then stretch it by a factor of\(\sqrt{n}\).mean_ = mean(sqrt(n) .* (sample_means .- mean(distribution))) std_ = sqrt(n) * std(sample_means) # Centered and stretched sample mean (r.v.) sample_means = sqrt(n) .* (sample_means .- mean(distribution)) # Getting Histogram num_bins = 50 bins = Array(LinRange(minimum(sample_means), maximum(sample_means), num_bins)) h = fit(Histogram, sample_means, bins) counts = h.weights Plots.histogram(sample_means, bins=bins, weights=(1/sum(counts)).*ones(length(sample_means))) # Getting PDF N(0, σ) x = LinRange(-3*std_, 3*std_, 100) pdf_ = pdf.(Normal(0, std_), x) plot!(x, pdf_, c="green", label="Normal distribution (PDF)", lw=3)Now the plot feels much more Normal but here the random variable is
\(\sqrt{n}\, (\overline{X}_n-\mu) \)not\(\overline{X}_n\).
And as we discussed earlier that,
Central Limit Theorem is not a statement about the convergence of PDF or PMF. It's a statement about the convergence of CDF.Now let's see ourselves,
# Plot CDF
# CDF of Normal Distribution
cdf_ = cdf.(Normal(samples_mean, samples_std), x)
plot(x, cdf_, c="green", label="Normal distribution CDF", lw=3)
# CDF of Sampling Distribution
cdf_ = cumsum(counts)/sum(counts)
pop!(bins)
scatter!(bins, cdf_, color="blue", label="Sampling distribution CDF")
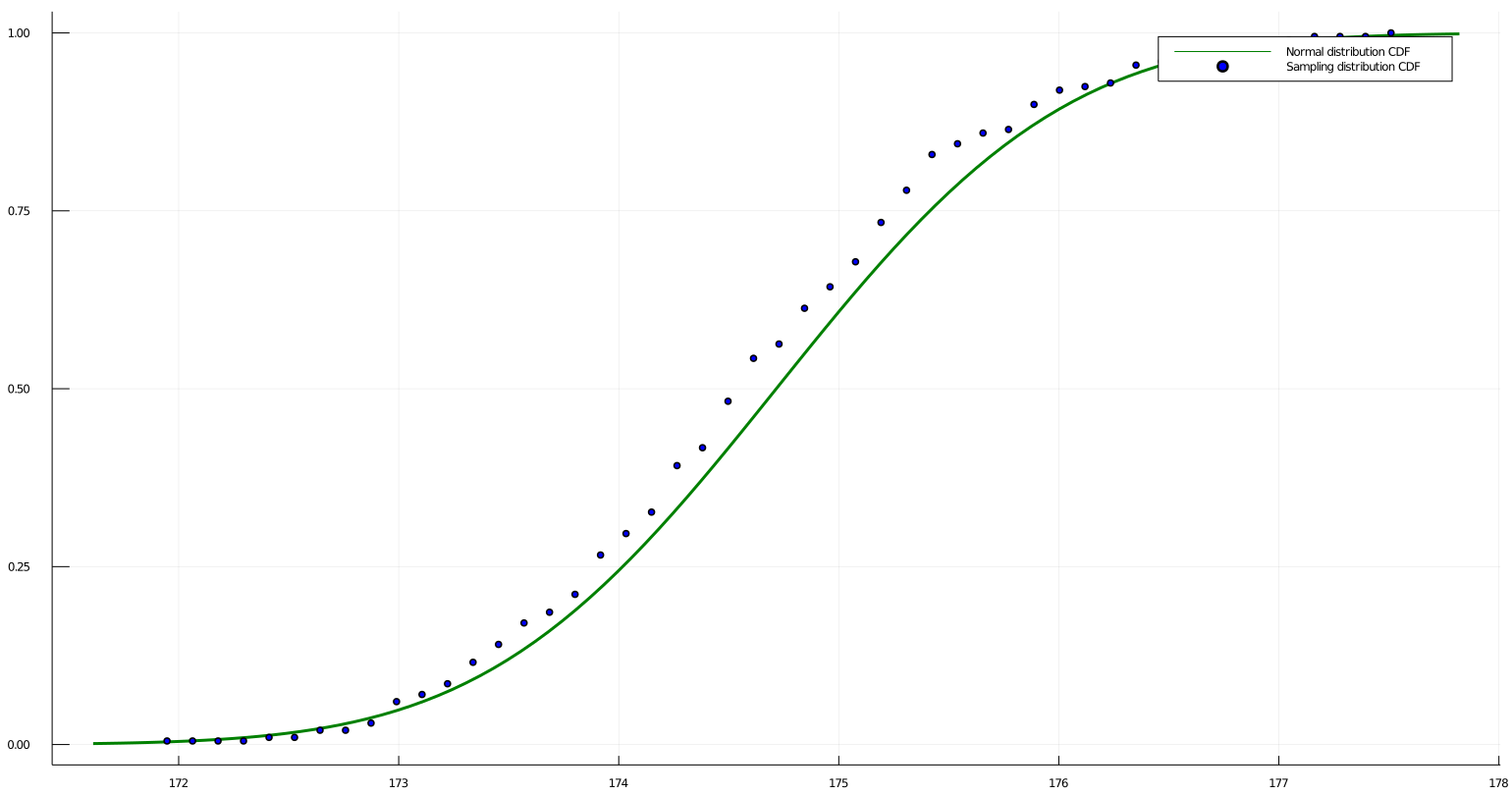 Here we can see the beauty of Central limit theorem, we can see how the CDF of our Sampling distribution get closer to the CDF of a Normal distribution.
Here we can see the beauty of Central limit theorem, we can see how the CDF of our Sampling distribution get closer to the CDF of a Normal distribution. Now try tweaking
\(n\)
and see how it affects the CDF convergence. Also try different distributions form Distributions.jl
Simulation
Visualize Central Limit Theorem
Try different distributions, tweak there parameters, sample size, number of simulations and see how it impacts the convergence of CDF of\(\overline{X}_n\).