

Table of Content
- \(1)\)Vector Space
- \(2)\)Column Space
- \(3)\)Null Space\((A\vec{x}=\vec{0})\)
- \(4)\)Solving\(A\vec{x}=\vec{b}\)
- \(5)\)Rank Of a Matrix
- \(6)\)\(\mathbf{4}\)fundamental subspaces
- \(7)\)Matrix Space
- \(8)\)Orthogonal Subspaces
- \(9)\)Projection
- \(10)\)Orthonormal column Vectors
- \(11)\)Eigenvalues and Eigenvectors
- \(12)\)Diagonalization and Power of a Matrix
- \(13)\)Differential Equation
- \(14)\)Markov Matrix & Fourier Series
- \(15)\)Symmetric Matrices Properties
- \(16)\)Complex Matrix & Fast Fourier Transform
- \(17)\)Positive Definite Matrices
- \(18)\)Similar Matrices
- \(19)\)Singular Value Decomposition
- \(19.0\)Introduction
- \(19.0.1\)Row Space
- \(19.0.2\)Null Space
- \(19.0.3\)Column Space
- \(19.0.4\)Left Null Space
- \(19.0.5\)Terminologies
- \(19.1\)Full SVD
- \(19.2\)Reduced SVD
- \(19.3\)Finding\(V\)and\(U\)Orthonormal matrix
- \(19.3.1\)Row space of\(A\)is same as Row space of\(A^TA\)
- \(19.3.2\)Column Space of\(A\)is same as Column Space of\(AA^T\)
- \(19.4\)Finding orthonormal Row vectors\((V)\)for matrix\(A\)
- \(19.5\)Finding orthonormal Column Vectors\((U)\)for matrix\(A\)
Fundamental Subspaces
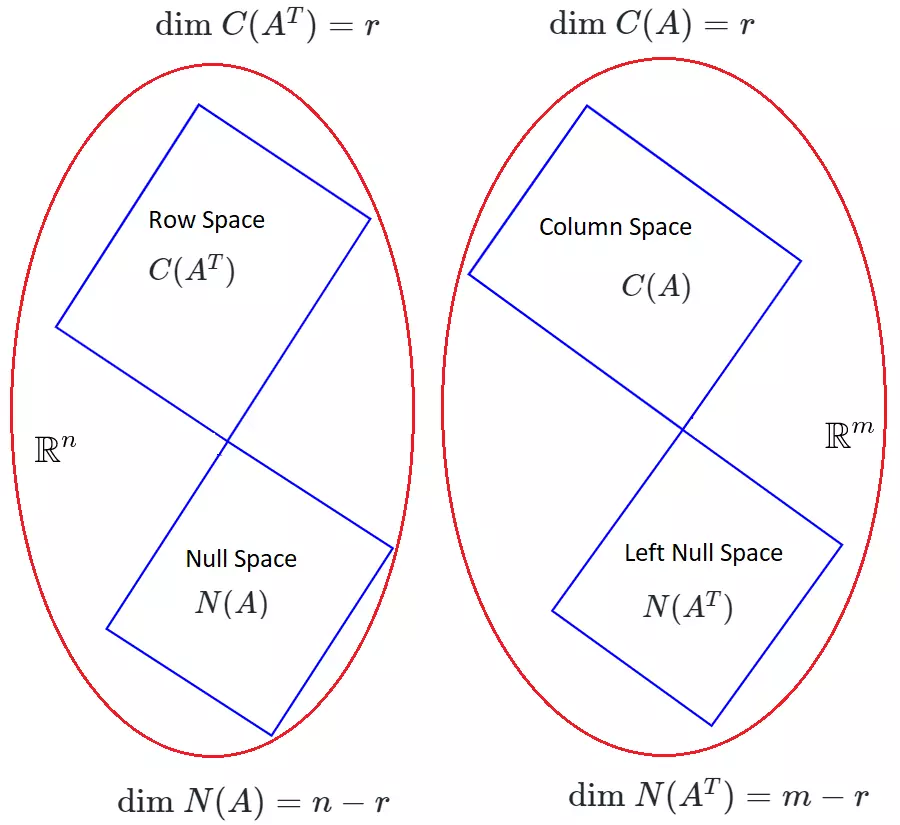
There are
\(4\)
fundamental subspaces (say we have a \(m\times n\)
matrix \(A\)
):\(1. \text{ Column Space } (C(A)) \)
\(2. \text{ Null Space } (N(A)) \)
\(3. \text{ Row Space } (C(A^T))\)
\(4. \text{ Left Null Space } (N(A^T))\)